
PostgreSQL High Availability Setup
PostgreSQL High Availability setup covers the installation and basic administration of PostgreSQL 17.2 in a pacemaker cluster on two VirtualBox VMs.
Table of Contents
Preparation of the PostgreSQL High Availability setup
To create a PostgreSQL High Availability (HA) system we need a basic pacemaker cluster consisting of two RedHat Enterprise Linux 8.10 nodes. The steps to setup these two machines are described here. On both nodes we install PostgreSQL as described in “Installation and setup of the PostgreSQL 17 server”.
Database configuration
The next step is the configuration of the databases for the PostgreSQL High Availability setup. Run the following commands:
# as root on both nodes
# set password of postgres database user
su - postgres -c "psql -c \"alter user postgres password 'changeme'\";"
# disable automatic startup of postgres
systemctl disable postgresql-17
# stop running database
systemctl stop postgresql-17
# create the archive directory
su - postgres -c 'mkdir /var/lib/pgsql/pg_archive'
# create ssh keys
echo ''|ssh-keygen -q -t rsa -N ''
su - postgres -c "echo ''|ssh-keygen -q -t rsa -N ''"
This needs to be done only on the first node:
(# as root on the first node
# configure passwordless ssh login for root and postgres
# for root
ssh-keyscan -t rsa lin2 >> ~/.ssh/known_hosts
sshpass -p changeme ssh-copy-id lin2
ssh lin2 'ssh-keyscan -t rsa lin1 >> ~/.ssh/known_hosts'
ssh lin2 sshpass -p changeme ssh-copy-id lin1
# for postgres
su - postgres -c 'ssh-keyscan -t rsa lin2 >> ~postgres/.ssh/known_hosts'
su - postgres -c 'sshpass -p changeme ssh-copy-id lin2'
su - postgres -c "ssh lin2 'ssh-keyscan -t rsa lin1 >> ~postgres/.ssh/known_hosts'"
su - postgres -c 'ssh lin2 sshpass -p changeme ssh-copy-id lin1'
# configure database
cat << EOF >> /var/lib/pgsql/17/data/postgresql.conf
# replication settings
listen_addresses = '*'
wal_level = hot_standby
synchronous_commit = on
archive_mode = on
archive_command = 'cp %p /var/lib/pgsql/pg_archive/%f'
max_wal_senders=5
hot_standby = on
restart_after_crash = off
wal_receiver_status_interval = 2
max_standby_streaming_delay = -1
max_standby_archive_delay = -1
synchronous_commit = on
restart_after_crash = off
hot_standby_feedback = on
EOF
cat << EOF >> /var/lib/pgsql/17/data/pg_hba.conf
# Allow connections from all other IPv4 hosts
host all all 0.0.0.0/0 scram-sha-256
# replication
host replication postgres 192.168.0.0/16 trust
host replication postgres 11.1.1.0/24 trust
EOF
# start postgres
su - postgres -c 'pg_ctl -D /var/lib/pgsql/17/data start')
Next we restore the slave database from the master. On the second node:
# as root on the second node
rm -rf /var/lib/pgsql/17/data/*
su - postgres -c 'cd /var/lib/pgsql/17/data/;pg_basebackup -h 192.168.0.1 -U postgres -D /var/lib/pgsql/17/data -X stream -P'
cat << EOF >> /var/lib/pgsql/17/data/postgresql.conf
primary_conninfo = 'host=192.168.0.1 port=5432 user=postgres application_name=node2'
restore_command = 'cp /var/lib/pgsql/pg_archive/%f %p'
recovery_target_timeline = 'latest'
EOF
su - postgres -c 'touch /var/lib/pgsql/17/data/standby.signal;pg_ctl -D /var/lib/pgsql/17/data start'
We can confirm that the replication is running:
# on node 1:
su - postgres -c "psql -c 'select application_name,client_addr,backend_start,backend_xmin,state,sent_lsn,write_lsn,flush_lsn,replay_lsn,write_lag,flush_lag,replay_lag,sync_state,reply_time from pg_stat_replication;'"
Output:
[root@lin1 ~]# # on node 1:
[root@lin1 ~]# su - postgres -c "psql -c 'select application_name,client_addr,backend_start,backend_xmin,state,sent_lsn,write_lsn,flush_lsn,replay_lsn,write_lag,flush_lag,replay_lag,sync_state,reply_time from pg_stat_replication;'"
application_name | client_addr | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_state | reply_time
------------------+-------------+------------------------------+--------------+-----------+-----------+-----------+-----------+------------+-----------+-----------+------------+------------+-------------------------------
node2 | 192.168.0.2 | 2025-02-09 11:40:48.85456+01 | 752 | streaming | 0/C000168 | 0/C000168 | 0/C000168 | 0/C000168 | | | | async | 2025-02-09 11:50:28.294068+01
(1 row)
[root@lin1 ~]#The next step is the creation of the pacemaker cluster resources. For that we need to stop the databases on both nodes:
# run as root on both nodes:
su - postgres -c 'pg_ctl -D /var/lib/pgsql/17/data stop'
Creation of the cluster resources
To create the cluster resources run the commands below on the first node. You might want to adjust the ip address 11.1.1.184 (it is just a free ip address in my network that will be available on the master node).
# as root on the first node:
pcs resource create pgvip ocf:heartbeat:IPaddr2 ip=11.1.1.184 nic=enp0s3 cidr_netmask=24
pcs resource create postgresql ocf:heartbeat:pgsql \
rep_mode=sync \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \
node_list="lin1 lin2" \
restore_command='cp /var/lib/pgsql/pg_archive/%f "%p"' \
master_ip=11.1.1.184 \
restart_on_promote=true \
pgdata=/var/lib/pgsql/17/data \
pgctl=/usr/pgsql-17/bin/pg_ctl
pcs resource promotable postgresql master-max=1 master-node-max=1 notify=true
pcs constraint colocation add pgvip with Promoted postgresql-clone INFINITY
pcs constraint order promote postgresql-clone then start pgvip symmetrical=false score=INFINITY
pcs constraint order demote postgresql-clone then stop pgvip symmetrical=false score=0
After both nodes rebootet the cluster is ready. This can be verified with:
pcs status --full
Output:
[root@lin1 ~]# pcs status –full
Cluster name: clu
Cluster Summary:
- Stack: corosync (Pacemaker is running)
- Current DC: lin2 (2) (version 2.1.7-5.2.el8_10-0f7f88312) – partition with quorum
- Last updated: Fri Feb 7 19:44:54 2025 on lin1
- Last change: Fri Feb 7 19:42:33 2025 by root via root on lin1
- 2 nodes configured
- 4 resource instances configured
Node List:
- Node lin1 (1): online, feature set 3.19.0
- Node lin2 (2): online, feature set 3.19.0
Full List of Resources:
- sbd_fencing (stonith:fence_sbd): Started lin1
- pgvip (ocf::heartbeat:IPaddr2): Started lin1
- Clone Set: postgresql-clone postgresql:
- postgresql (ocf::heartbeat:pgsql): Master lin1
- postgresql (ocf::heartbeat:pgsql): Slave lin2
Node Attributes:
- Node: lin1 (1):
- master-postgresql : 1000
- postgresql-data-status : LATEST
- postgresql-master-baseline : 00000000040000A0
- postgresql-status : PRI
- Node: lin2 (2):
- master-postgresql : 100
- postgresql-data-status : STREAMING|SYNC
- postgresql-status : HS:sync
Migration Summary:
Tickets:
PCSD Status:
lin1: Online
lin2: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
sbd: active/enabled
[root@lin1 ~]#
Terms used:
| postgresql-data-status: LATEST | PostgreSQL is master. |
| postgresql-data-status: DISCONNECT | The master can’t see the connection of the HS, so the state of the HS is set to DISCONNECT. |
| postgresql-status: PRI | PostgreSQL works as a primary (master) |
| postgresql-status: STOP | PostgreSQL is stopped. |
| postgresql-status: HS:alone | PostgreSQL works as Hot Standby. |
| postgresql-status: HS:STREAMING|ASYNC | PostgreSQL works as Hot Standby. Write transactions on the primary don’t wait for confirmation from the HS. HS can be used for Read Only queries. |
| postgresql-status: HS:STREAMING|SYNC | PostgreSQL works as Hot Standby. Write transaction on the primary wait for the HS to confirm data is written to the WAL on the HS. HS can be used for Read Only queries. |
more info see here.
Administration and Troubleshooting
Rebuild the standby database
If there is a failure on the standby database that cannot be resolved otherwise, we can always rebuild the standby database from the current master:
# run as root on the standby db that should be rebuilt
# check if a lock file exists on the standby db and remove it.
rm -fv /var/lib/pgsql/tmp/PGSQL.lock
# this will temp. remove the node from the cluster and stop postgres
pcs node standby lin2
sleep 2
# remove old data
rm -rf /var/lib/pgsql/17/data/*
# restore data from the current master (lin1/192.168.0.1)
su - postgres -c 'pg_basebackup -h 192.168.0.1 -U postgres -D /var/lib/pgsql/17/data -X stream -P'
# let the standby re-join the cluster and start replicating
pcs node unstandby lin2
requested WAL segment has already been removed / waiting for WAL to become available
Error messages in the postgres logfile on a standby database like these
2025-02-09 11:12:52.868 CET [11870] LOG: started streaming WAL from primary at 0/9000000 on timeline 1
2025-02-09 11:12:52.868 CET [11870] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000000000009 has already been removed
cp: cannot stat '/var/lib/pgsql/pg_archive/00000002.history': No such file or directory
2025-02-09 11:12:52.871 CET [4217] LOG: waiting for WAL to become available at 0/9000168
cp: cannot stat '/var/lib/pgsql/pg_archive/000000010000000000000009': No such file or directoryhappen for example when the primary has already archived a WAL file that is now needed from the standy. To solve it just copy the archived WAL file from the master to the standby:
# on the master:
su - postgres -c 'scp /var/lib/pgsql/pg_archive/000000010000000000000009 lin2:/var/lib/pgsql/pg_archive/'Web UI for cluster monitoring / administration
The pcsd Web UI can be used to monitor and administer the cluster. Login with hacluster / changeme and click on Add Existing (add one of the nodes, e.g. lin1). The we interface looks like this:
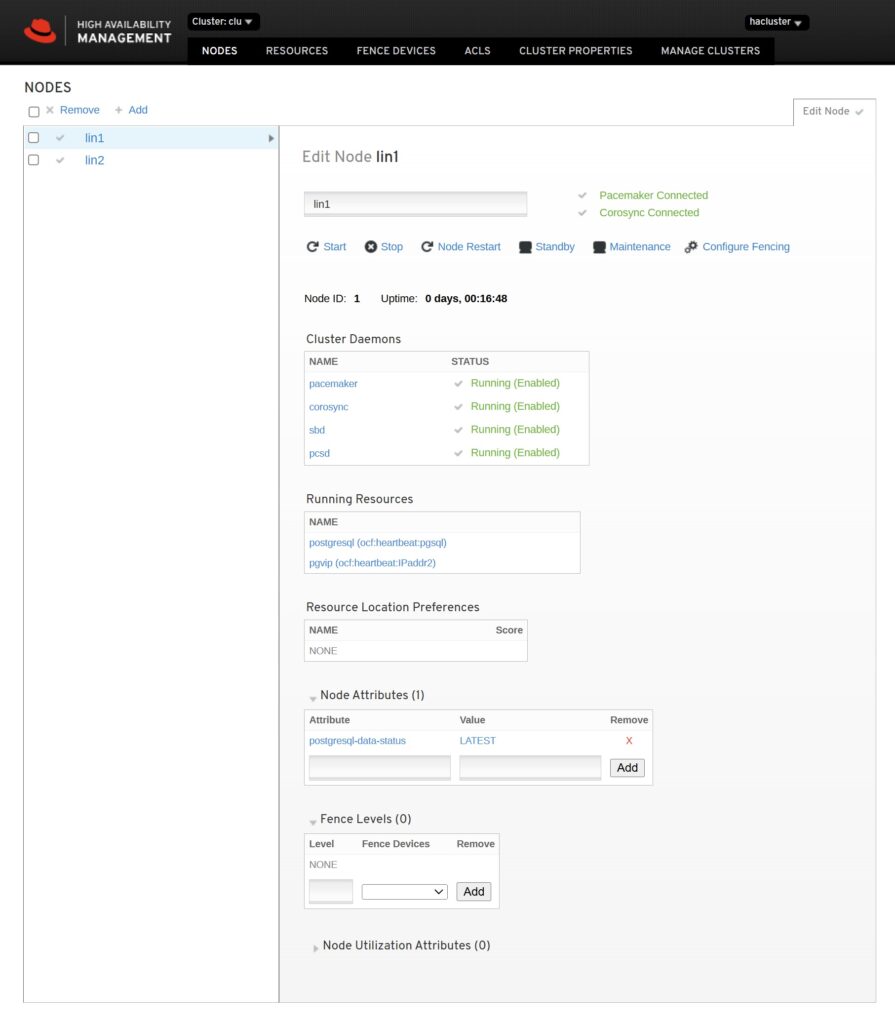
Further info
- PostgreSQL cluster resource man page: man ocf_heartbeat_pgsql
- GitHub PostgreSQL Resource Agent
- HA Clustering of PostgreSQL(replication)
- The PostgreSQL resource agents logs into /var/log/pacemaker/pacemaker.log
- After a role switch the previous master need to be always restored from the current master! For a explanation take a look here.
# location of the pgsgl resource agent
/usr/lib/ocf/resource.d/heartbeat/pgsql
# get metadata of the resouce agent (e.g. version)
export OCF_ROOT=/usr/lib/ocf
$OCF_ROOT/resource.d/heartbeat/pgsql meta-data
# clean the errors of a failed resource
pcs resource cleanup postgresql
# show resource config
pcs resource config postgresqlSample output of some commands:
[root@lin1 ~]# pcs resource config postgresql
Resource: postgresql (class=ocf provider=heartbeat type=pgsql)
Attributes: postgresql-instance_attributes
master_ip=11.1.1.184
node_list="lin1 lin2"
pgctl=/usr/pgsql-17/bin/pg_ctl
pgdata=/var/lib/pgsql/17/data
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5"
rep_mode=sync
restart_on_promote=true
restore_command='cp /var/lib/pgsql/pg_archive/%f "%p"'
Operations:
demote: postgresql-demote-interval-0s
interval=0s
timeout=120s
methods: postgresql-methods-interval-0s
interval=0s
timeout=5s
monitor: postgresql-monitor-interval-30s
interval=30s
timeout=30s
monitor: postgresql-monitor-interval-29s
interval=29s
timeout=30s
role=Master
notify: postgresql-notify-interval-0s
interval=0s
timeout=90s
promote: postgresql-promote-interval-0s
interval=0s
timeout=120s
start: postgresql-start-interval-0s
interval=0s
timeout=120s
stop: postgresql-stop-interval-0s
interval=0s
timeout=120s
[root@lin1 ~]#
Leave a Reply